Istio is the future!基本上,我相信对云原生技术趋势有些微判断的同学,都会有这个觉悟。其背后的逻辑其实是比较简单的:当容器集群,特别是K8S成为事实上的标准之后,应用必然会不断的复杂化,服务治理肯定会成为强需求。
Istio的现状是,聊的人很多,用的人其实很少。所以导致我们能看到的文章,讲道理的很多,讲实际踩坑经验的极少。
阿里云售后团队作为一线踩坑团队,分享问题排查经验,我们责无旁贷。这篇文章,我就跟大家聊一个简单Istio问题的排查过程,权当抛砖。
二分之一活的微服务
问题是这样的,用户在自己的测试集群里安装了Istio,并依照官方文档部署bookinfo应用来上手Istio。部署之后,用户执行kubectl get pods命令,发现所有的pods都只有二分之一个容器是READY的。
# kubectl get podsNAME READY STATUS RESTARTS AGEdetails-v1-68868454f5-94hzd 1/2 Running 0 1mproductpage-v1-5cb458d74f-28nlz 1/2 Running 0 1mratings-v1-76f4c9765f-gjjsc 1/2 Running 0 1mreviews-v1-56f6855586-dplsf 1/2 Running 0 1mreviews-v2-65c9df47f8-zdgbw 1/2 Running 0 1mreviews-v3-6cf47594fd-cvrtf 1/2 Running 0 1m
如果从来都没有注意过READY这一列的话,我们大概会有两个疑惑:2在这里是什么意思,以及1/2到底意味着什么。
简单来讲,这里的READY列,给出的是每个pod内部容器的readiness,即就绪状态。每个集群节点上的kubelet会根据容器本身readiness规则的定义,分别是tcp、http或exec的方式,来确认对应容器的readiness情况。
更具体一点,kubelet作为运行在每个节点上的进程,以tcp/http的方式(节点网络命名空间到pod网络命名空间)访问容器定义的接口,或者在容器的namespace里执行exec定义的命令,来确定容器是否就绪。
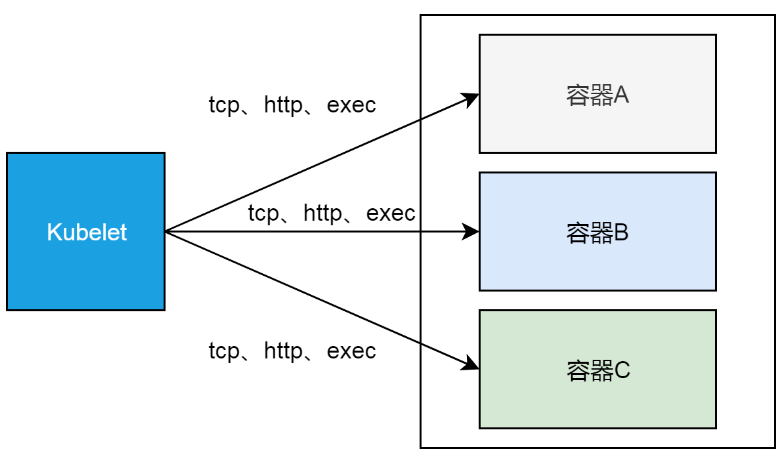
这里的2说明这些pod里都有两个容器,1/2则表示,每个pod里只有一个容器是就绪的,即通过readiness测试的。关于2这一点,我们下一节会深入讲,这里我们先看一下,为什么所有的pod里,都有一个容器没有就绪。
使用kubectl工具拉取第一个details pod的编排模板,可以看到这个pod里两个容器,只有一个定义了readiness probe。对于未定义readiness probe的容器,kubelet认为,只要容器里的进程开始运行,容器就进入就绪状态了。所以1/2个就绪pod,意味着,有定义readiness probe的容器,没有通过kubelet的测试。
没有通过readiness probe测试的是istio-proxy这个容器。它的readiness probe规则定义如下。
readinessProbe: failureThreshold: 30 httpGet: path: /healthz/ready port: 15020 scheme: HTTP initialDelaySeconds: 1 periodSeconds: 2 successThreshold: 1 timeoutSeconds: 1
我们登录这个pod所在的节点,用curl工具来模拟kubelet访问下边的uri,测试istio-proxy的就绪状态。
# curl http://172.16.3.43:15020/healthz/ready -v* About to connect() to 172.16.3.43 port 15020 (#0)* Trying 172.16.3.43...* Connected to 172.16.3.43 (172.16.3.43) port 15020 (#0)> GET /healthz/ready HTTP/1.1> User-Agent: curl/7.29.0> Host: 172.16.3.43:15020> Accept: */*> < HTTP/1.1 503 Service Unavailable< Date: Fri, 30 Aug 2019 16:43:50 GMT< Content-Length: 0< * Connection #0 to host 172.16.3.43 left intact
绕不过去的大图
上一节我们描述了问题现象,但是留下一个问题,就是pod里的容器个数为什么是2。虽然每个pod本质上至少有两个容器,一个是占位符容器pause,另一个是真正的工作容器,但是我们在使用kubectl命令获取pod列表的时候,READY列是不包括pause容器的。
这里的另外一个容器,其实就是服务网格的核心概念sidercar。其实把这个容器叫做sidecar,某种意义上是不能反映这个容器的本质的。Sidecar容器本质上是反向代理,它本来是一个pod访问其他服务后端pod的负载均衡。
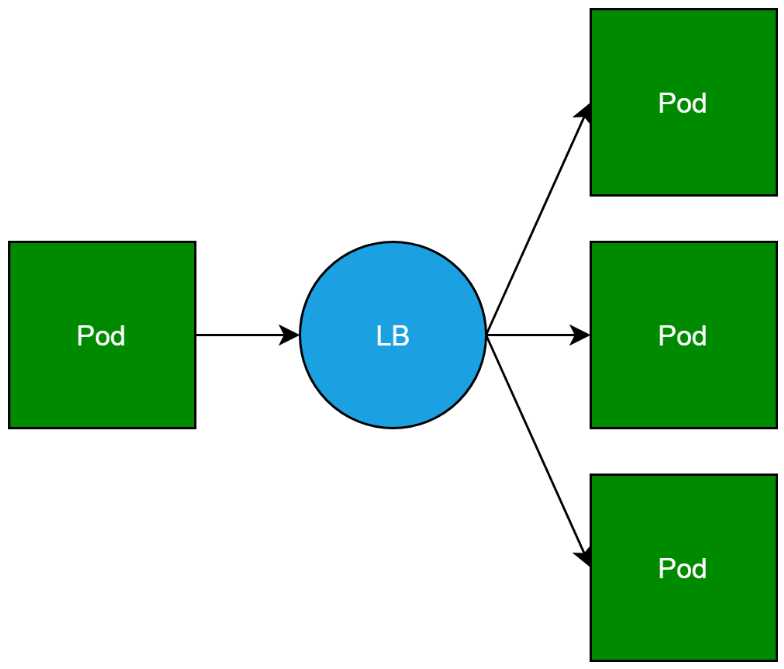
然而,当我们为集群中的每一个pod,都“随身”携带一个反向代理的时候,pod和反向代理就变成了服务网格。正如下边这张经典大图所示。这张图实在有点难画,所以只能借用,绕不过去。
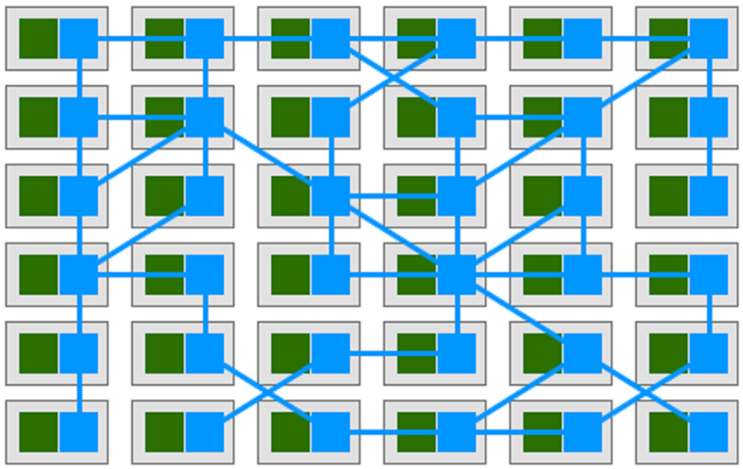
所以sidecar模式,其实是“自带通信员”模式。这里比较有趣的是,在我们把sidecar和pod绑定在一块的时候,sidecar在出流量转发时扮演着反向代理的角色,而在入流量接收的时候,可以做超过反向代理职责的一些事情。这点我们会在其他文章里讨论。
Istio在K8S基础上实现了服务网格,Isito使用的sidecar容器就是第一节提到的,没有就绪的容器。所以这个问题,其实就是服务网格内部,所有的sidecar容器都没有就绪。
代理与代理的生命周期管理
上一节我们看到,istio中的每个pod,都自带了反向代理sidecar。我们遇到的问题是,所有的sidecar都没有就绪。我们也看到readiness probe定义的,判断sidecar容器就绪的方式就是访问下边这个接口。
http://:15020/healthz/ready
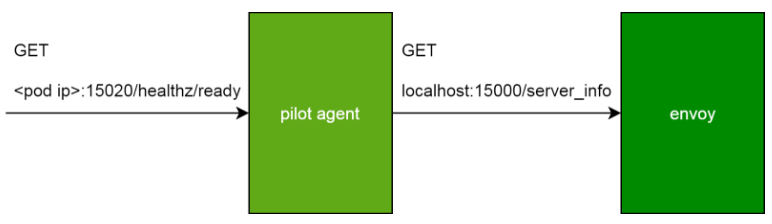
接下来,我们深入看下pod,以及其sidecar的组成及原理。在服务网格里,一个pod内部除了本身处理业务的容器之外,还有istio-proxy这个sidecar容器。正常情况下,istio-proxy会启动两个进程,pilot-agent和envoy。
如下图,envoy是实际上负责流量管理等功能的代理,从业务容器出、入的数据流,都必须要经过envoy;而pilot-agent负责维护envoy的静态配置,以及管理envoy的生命周期。这里的动态配置部分,我们在下一节会展开来讲。
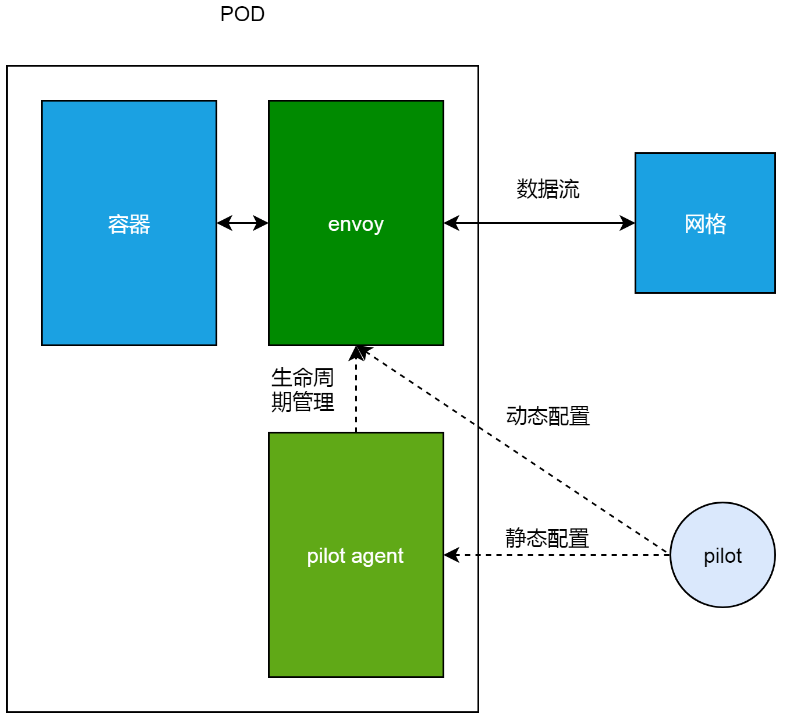
我们可以使用下边的命令进入pod的istio-proxy容器做进一步排查。这里的一个小技巧,是我们可以以用户1337,使用特权模式进入istio-proxy容器,如此就可以使用iptables等只能在特权模式下运行的命令。
docker exec -ti -u 1337 --privilegedbash
这里的1337用户,其实是sidecar镜像里定义的一个同名用户istio-proxy,默认sidecar容器使用这个用户。如果我们在以上命令中,不使用用户选项u,则特权模式实际上是赋予root用户的,所以我们在进入容器之后,需切换到root用户执行特权命令。
进入容器之后,我们使用netstat命令查看监听,我们会发现,监听readiness probe端口15020的,其实是pilot-agent进程。
istio-proxy@details-v1-68868454f5-94hzd:/$ netstat -lnptActive Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program nametcp 0 0 0.0.0.0:15090 0.0.0.0:* LISTEN 19/envoytcp 0 0 127.0.0.1:15000 0.0.0.0:* LISTEN 19/envoytcp 0 0 0.0.0.0:9080 0.0.0.0:* LISTEN -tcp6 0 0 :::15020 :::* LISTEN 1/pilot-agent
我们在istio-proxy内部访问readiness probe接口,一样会得到503的错误。
就绪检查的实现
了解了sidecar的代理,以及管理代理生命周期的pilot-agent进程,我们可以稍微思考一下pilot-agent应该怎么去实现healthz/ready这个接口。显然,如果这个接口返回OK的话,那不仅意味着pilot-agent是就绪的,而必须确保代理是工作的。
实际上pilot-agent就绪检查接口的实现正是如此。这个接口在收到请求之后,会去调用代理envoy的server_info接口。调用所使用的的IP是localhost。这个非常好理解,因为这是同一个pod内部进程通信。使用的端口是envoy的proxyAdminPort,即15000。
有了以上的知识准备之后,我们来看下istio-proxy这个容器的日志。实际上,在容器日志里,一直在重复输出一个报错,这句报错分为两部分,其中Envoy proxy is NOT ready这部分是pilot agent在响应healthz/ready接口的时候输出的信息,即Envoy代理没有就绪;而剩下的config not received from Pilot (is Pilot running?): cds updates: 0 successful, 0 rejected; lds updates: 0 successful, 0 rejected这部分,是pilot-agent通过proxyAdminPort访问server_info的时候带回的信息,看起来是envoy没有办法从Pilot获取配置。
Envoy proxy is NOT ready: config not received from Pilot (is Pilot running?): cds updates: 0 successful, 0 rejected; lds updates: 0 successful, 0 rejected.
到这里,建议大家回退看下上一节的插图,在上一节我们选择性的忽略是Pilot到envoy这条虚线,即动态配置。这里的报错,实际上是envoy从控制面Pilot获取动态配置失败。
控制面和数据面
目前为止,这个问题其实已经很清楚了。在进一步分析问题之前,我聊一下我对控制面和数据面的理解。控制面数据面模式,可以说无处不在。我们这里举两个极端的例子。
第一个例子,是dhcp服务器。我们都知道,在局域网中的电脑,可以通过配置dhcp来获取ip地址,这个例子中,dhcp服务器统一管理,动态分配ip地址给网络中的电脑,这里的dhcp服务器就是控制面,而每个动态获取ip的电脑就是数据面。
第二个例子,是电影剧本,和电影的演出。剧本可以认为是控制面,而电影的演出,包括演员的每一句对白,电影场景布置等,都可以看做是数据面。
我之所以认为这是两个极端,是因为在第一个例子中,控制面仅仅影响了电脑的一个属性,而第二个例子,控制面几乎是数据面的一个完整的抽象和拷贝,影响数据面的方方面面。Istio服务网格的控制面是比较靠近第二个例子的情况,如下图。
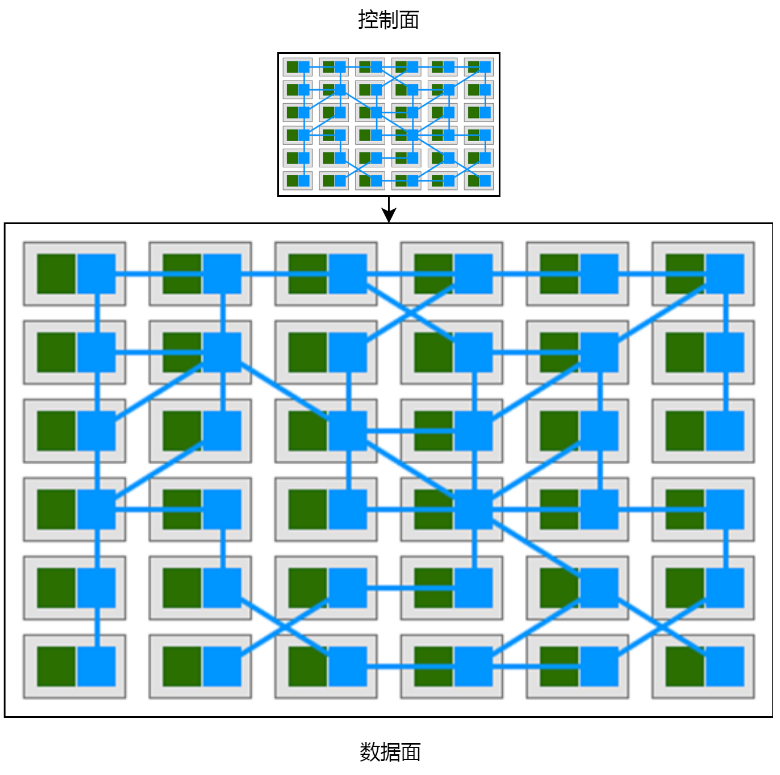
Istio的控制面Pilot使用grpc协议对外暴露接口istio-pilot.istio-system:15010,而envoy无法从Pilot处获取动态配置的原因,是在所有的pod中,集群dns都无法使用。
简单的原因
这个问题的原因其实比较简单,在sidecar容器istio-proxy里,envoy不能访问Pilot的原因是集群dns无法解析istio-pilot.istio-system这个服务名字。在容器里看到resolv.conf配置的dns服务器是172.19.0.10,这个是集群默认的kube-dns服务地址。
istio-proxy@details-v1-68868454f5-94hzd:/$ cat /etc/resolv.confnameserver 172.19.0.10search default.svc.cluster.local svc.cluster.local cluster.local localdomain
但是客户删除重建了kube-dns服务,且没有指定服务IP,这导致,实际上集群dns的地址改变了,这也是为什么所有的sidecar都无法访问Pilot。
# kubectl get svc -n kube-systemNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkube-dns ClusterIP 172.19.9.5453/UDP,53/TCP 5d
最后,通过修改kube-dns服务,指定IP地址,sidecar恢复正常。
# kubectl get podsNAME READY STATUS RESTARTS AGEdetails-v1-68868454f5-94hzd 2/2 Running 0 6dnginx-647d5bf6c5-gfvkm 2/2 Running 0 2dnginx-647d5bf6c5-wvfpd 2/2 Running 0 2dproductpage-v1-5cb458d74f-28nlz 2/2 Running 0 6dratings-v1-76f4c9765f-gjjsc 2/2 Running 0 6dreviews-v1-56f6855586-dplsf 2/2 Running 0 6dreviews-v2-65c9df47f8-zdgbw 2/2 Running 0 6dreviews-v3-6cf47594fd-cvrtf 2/2 Running 0 6d
结论
这其实是一个比较简单的问题,排查过程其实也就几分钟。但是写这篇文章,有点感觉是在看长安十二时辰,短短几分钟的排查过程,写完整背后的原理,前因后果,却花了几个小时。这是Istio文章的第一篇,希望在大家排查问题的时候,有所帮助。
本文为云栖社区原创内容,未经允许不得转载。